Web Archive Interface: Instructions for the Summary, Explore, and Site map tools.
In this article we will talk about web.archive itself and how it works.
For reference: web archive was created by Brewster Cale in 1996 about at the same time when he founded Alexa Internet, a company that collects statistics on website traffic. In October of that year, company started archiving and storing copies of web pages. But the current form called WAYBACKMACHINE, that we can use now, started only in 2001, although the data has been saved since 1996. Web archive advantage for any website is that it saves not only the html-code of the pages, but also other file types: doc, zip, avi, jpg, pdf, css. A complex of html-codes of all page elements allows you to restore the site in its original form (on a specific indexing date when web archive spider visited the site’s pages).
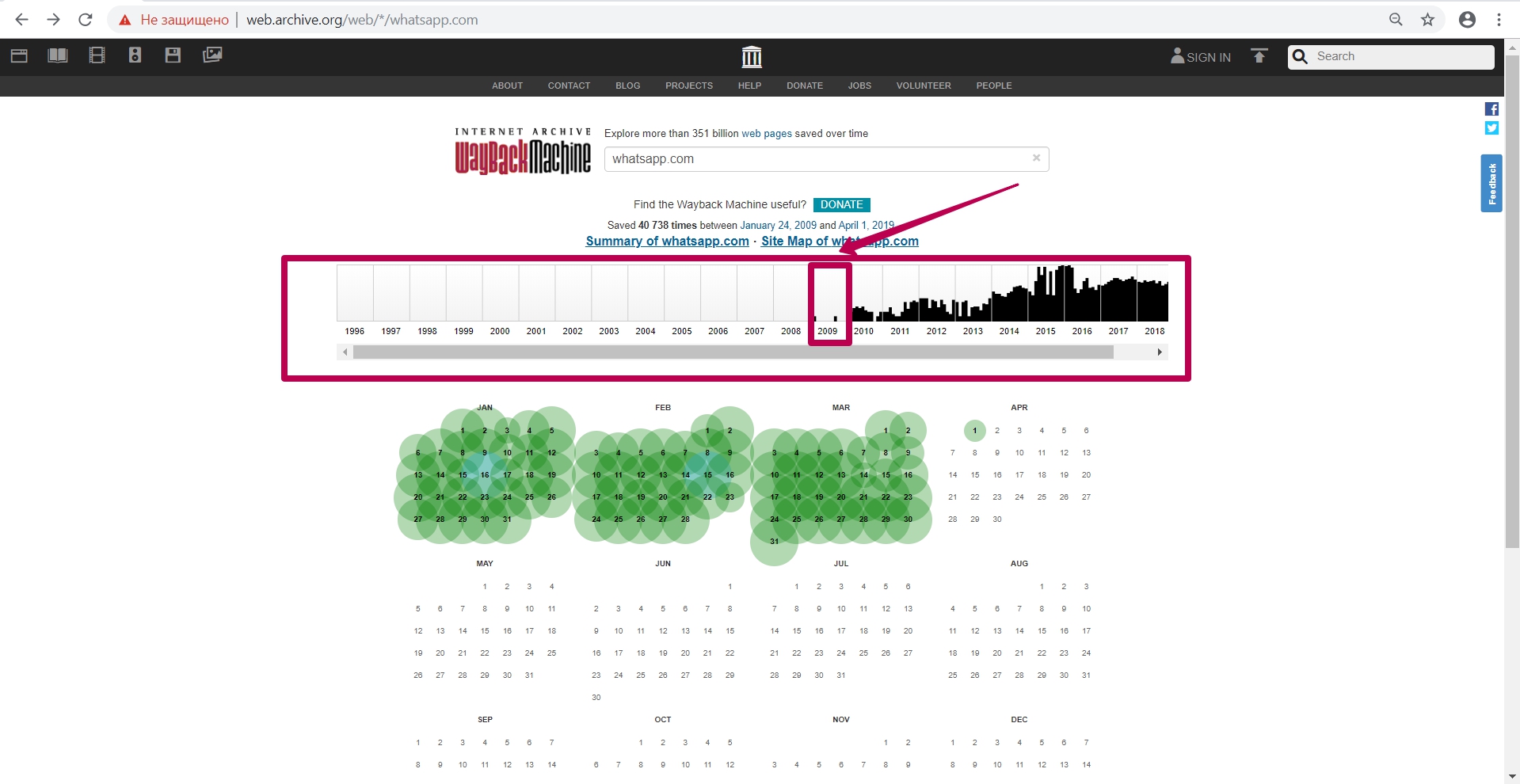
So, archive is located at http://web.archive.org/. Let’s touch on web archive possibilities on the example of a well-known website as WhatsApp.
Enter website domain on the main page in the search field. In our case it will be whatsapp.com.
Read more – https://en.archivarix.com/blog/1-how-does-it-works-archiveorg/
How to restore websites from the Web Archive – archive.org. Part 2
How to restore websites from the Web Archive – archive.org. Part 3
